

LEARN | Module 3
Critical Appraisal of Studies of Therapy
Drug companies, reputable authorities, patients, colleagues and the media all show interest in the latest research on a particular topic. Each reads and interprets this data in a particular way, leading to the potential for misinterpretation, misinformation and overall negative outcomes for patients. It is therefore of utmost importance that we, as doctors, understand how to critically appraise a study (i.e. analyse whether its results are valid, what those results are and whether they will help in caring for our patients). Performing critical appraisals will form the basis of this week’s discussions. As always, please post any questions, comments or suggestions in the Disqus comment feed at the bottom of the module!
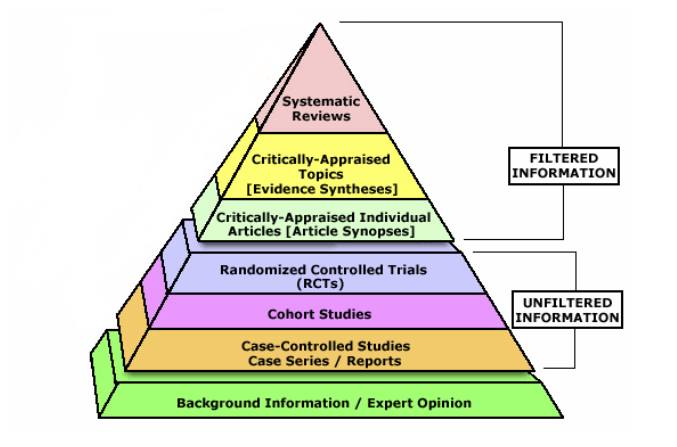
The evidence hierarchy
The following pyramid shows the general ranking of different types of evidence. Note that it is not absolute – a well designed cohort study may be more valid in answering a particular question than a poorly designed (or executed) randomised control trial.
Statistical significance
A test of statistical significance determines the probability that the results of a study were due to chance rather than an interventional effect. If this is not accounted for, a study could be a “random error” or statistical variation. One way we look at statistical significance is by checking the p-value, which we have arbitrarily assigned < 0.05 as a cut-off for statistical significance. This was discussed in more detail in week 2.
Clinical significance
Note that there are two main types of result: patient-oriented outcomes (e.g. pain scores, mortality, etc) and disease-oriented outcomes (e.g. HbA1c, blood pressure, lung function tests). To be clinically significant, the risks and benefits of a particular intervention must be looked at together (e.g. warfarin use for stroke prevention in atrial fibrillation). A further measure of clinical significance is the number needed to treat, which is also helpful when analysing the financial cost:benefit ratio.
Bias and validity
The validity of a study is a measure of how well it prevents biases (or sources of error). There are four main types of bias:
Selection bias occurs when the allocation of subjects to control and intervention groups leads to groups with dissimilar characteristics that may alter the result of the experiment (e.g. the intervention group has a much higher mean and median age, resulting in biased results for occurrence of ischaemic heart disease). We prevent selection bias using hidden, computer generated randomisation.
Performance bias occurs when there is change in the care provided to a subject due to the provider’s knowledge of which group they are in (e.g. a doctor giving a proton pump inhibitor to someone to prevent stomach ulcers because they know the patient is in the NSAID arm of a study vs. placebo). Double blinding, where the assessor/provider does not and cannot know which arm the subject is in, prevents performance bias.
Attrition bias is when the differences between the groups of a trial at the end of the trial might be under- or overestimated based on people who have dropped out (or exited) the study, possibly because of an interventional effect. Intention to treat analysis (using worst and best case scenarios) controls for attrition bias.
Detection bias is when an outcome assessor treats people in different arms of the study differently (e.g. in a study for a drug for pain relief, the assessor asks treatment arm subjects about their pain reduction vs. control arm subjects about whether their pain worsened). It can be prevented by blinding the outcome assessors.
Selective reporting
Selective reporting of positive outcomes and failing to report negative outcomes may introduce bias and alter the usability of results.
Precision
Narrower confidence intervals mean that a study is more precise in predicting the true effect of an intervention, whatever that effect may be.
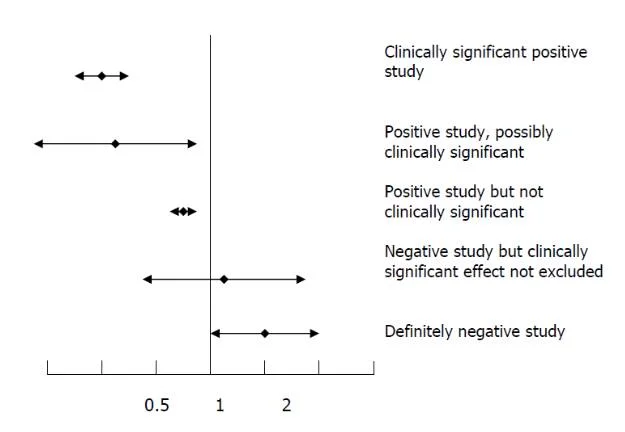
Negative studies
Negative studies are only truly negative if the minimum benefit of clinical significance lies beyond the confidence interval (just as a truly positive study must have a confidence interval completely beyond the minimum benefit of clinical significance).
Measures of treatment effect
Absolute risk reduction (ARR) is the difference in rate of the measured outcome between the intervention and control groups. For example, the death rate in the control group minus the death rate in intervention group. Note that if we are referring to the "risk" of cure, then ARR may be negative – the intervention group has an increased risk of cure.
Relative risk (or relative risk ratio, RR) is the ratio of the event rate in the intervention to the event rate in the control groups. For example, the death rate in the intervention group divided by the death rate in the control group. Note that a relative risk for harm (death) of 0.5-1 is weak, 0.125-0.5 is moderate and <0.125 is strong. A relative risk for benefit (cure) of 1-2 is weak, 2-4 is moderate and >4 is strong.
Relative risk reduction (RRR) is the difference in outcome event rates divided by the event rate of the control group. It can also be calculated as 1 minus the relative risk. For example, in a study where the relative risk of death is 0.75 (i.e. the intervention group had 0.75 times the rate of death as the control group), the relative risk reduction is 0.25 (i.e. the intervention decreases your rate of death by 25%). In a study where the relative "risk" of cure is 1.3 (i.e. the intervention group had 1.3 times the rate of cure as the control group), the relative risk reduction is -0.3 (i.e. the intervention increases your rate of cure by 30%).
Number needed to treat (NNT) is the reciprocal of the absolute risk reduction. It is the number of people needed to give the intervention to in order to prevent a bad outcome or achieve a good outcome. For example, in a study where the "risk" was cure, a NNT of 5 people means that giving 5 people the tested intervention will mean that one of them is likely to be cured (on average).
External validity and generalisability
This looks at whether the results of a trial are valid for your patient. Would they fit the inclusion and exclusion criteria or are people like them not accounted for in the trial?
Critical appraisal guide for studies of therapy
Here is a guide for which questions to ask when performing a critical appraisal of a study of therapy. Studies of harm will be discussed in a future module.
Are the results of this study valid?
Was the assignment of patients to treatments randomised?
Was the randomisation list concealed?
Were the groups similar at the start of the trial?
Were patients and clinicians kept "blind" to treatment?
Was the follow-up of patients sufficiently long and complete?
Were all patients analysed in the groups to which they were randomised?
Were study personnel (i.e. outcome assessors) kept "blind" to treatment?
Were the groups treated equally, apart from the experimental treatment?
What are the results?
What is the relative risk/risk ratio?
How large was the treatment effect?
How precise was the estimate of the treatment effect?
How can I apply the results to patient care?
Were the study patients similar to the patient under consideration in my practice?
Is the treatment feasible in your setting?
Were all clinically important outcomes considered?
Are the likely treatment benefits worth the potential harms and costs?